Creating a serverless pipeline using AWS CDK alongside AWS Lambda in Python allows for event-driven applications which can easily be scaled without worrying about the underlying infrastructure. This article describes the process of creating and setting up a serverless pipeline step by step in AWS CDK and Python Lambda with Visual Studio Code (VS Code) as the IDE.
Completing this guide enables the deployment of a fully working AWS Lambda function with AWS CDK.
Understanding Serverless Architecture and Its Benefits
A serverless architecture is a cloud computing paradigm where the developers need to write the code as functions and these functions get executed upon receiving an event or request. These functions will execute without any server provisioning or management. Execution and resource allocation are automatically managed by the cloud provider – in this instance, AWS.
Key Characteristics of Serverless Architecture:
- Event-Driven: Functions are triggered by events such as S3 uploads, API calls, or other AWS service actions.
- Automatic Scaling: The platform automatically scales based on workload, handling high traffic without requiring manual intervention.
- Cost Efficiency: Users pay only for the compute time used by the functions, making it cost-effective, especially for workloads with varying traffic.
Benefits:
Serverless architecture comes with numerous advantages that are beneficial for modern applications in the cloud. One of the most notable benefits of serverless architecture is improved operational efficiency due to the lack of server configuration and maintenance. Developers are free to focus on building and writing code instead of worrying about managing infrastructure.
Serverless architecture has also enabled better workload management because automatic scaling allows serverless platforms to adjust to changing workloads without human interaction, making traffic spikes effortless. This kind of adaptability maintains high performance and efficiency while minimizing costs and resource waste.
In addition, serverless architecture has proven to be financially efficient, allowing users to pay solely for the computing resources they utilize, as opposed to pre-purchased server capacity. This flexibility is advantageous for workloads with unpredictable or fluctuating demand. Finally, the ease of use provided by serverless architecture leads to an accelerated market launch because developers can rapidly build, test, and deploy applications without the tedious task of configuring infrastructure, leading to faster development cycles.
Understanding ETL Pipelines and Their Benefits
ETL (Extract, Transform, Load) pipelines automate the movement and transformation of data between systems. In the context of serverless, AWS services like Lambda and S3 work together to build scalable, event-driven data pipelines.
Key Benefits of ETL Pipelines:
- Data Integration: Combines disparate data sources into a unified system.
- Scalability: Services like AWS Glue and S3 scale automatically to handle large datasets.
- Automation: Use AWS Step Functions or Python scripts to orchestrate tasks with minimal manual intervention.
- Cost Efficiency: Pay-as-you-go pricing models for services like Glue, Lambda, and S3 optimize costs.
Tech Stack Used in the Project
For this serverless ETL pipeline, Python is the programming language of choice while Visual Studio Code serves as the IDE. The architecture is built around AWS services such as AWS CDK for resource definition and deployment, Amazon S3 as the storage service, and AWS Lambda for running serverless functions. All these in combination build a strong robust and scalable serverless data pipeline.
The versatility and simplicity associated with Python, as well as its extensive library collection, make it an ideal language for Lambda functions and serverless applications. With AWS’s CDK (Cloud Development Kit), the deployment of cloud resources is made easier because infrastructure can be defined programmatically in Python and many other languages. AWS Lambda is a serverless compute service which scales automatically and charges only when functions are executed, making it very cost-effective for event-driven workloads. Amazon S3 is a highly scalable object storage service that features prominently in serverless pipelines as a staging area for raw data and the final store for the processed results. These components create the building blocks of a cost-effective and scalable serverless data pipeline.
- Language: Python
- IDE: Visual Studio Code
- AWS Services:
- AWS CDK: Infrastructure as Code (IaC) tool to define and deploy resources.
- Amazon S3: Object storage for raw and processed data.
- AWS Lambda: Serverless compute service to transform data.
- AWS CDK: Infrastructure as Code (IaC) tool to define and deploy resources.
Brief Description of Tools and Technologies:
- Python: A versatile programming language favored for its simplicity and vast ecosystem of libraries, making it ideal for Lambda functions and serverless applications.
- AWS CDK (Cloud Development Kit): An open-source framework that allows you to define AWS infrastructure in code using languages like Python. It simplifies the deployment of cloud resources.
- AWS Lambda: A serverless compute service that runs code in response to events. Lambda automatically scales and charges you only for the execution time of your function.
- Amazon S3: A scalable object storage service for storing and retrieving large amounts of data. In serverless pipelines, it acts as both a staging and final storage location for processed data.
Building the Serverless ETL Pipeline – Step by Step
In this tutorial, we’ll guide you through setting up a serverless pipeline using AWS CDK and AWS Lambda in Python. We’ll also use Amazon S3 to store data.
Step 1: Prerequisites
To get started, ensure you have the following installed on your local machine:
- Node.js (v18 or later) → Download Here
- AWS CLI (Latest version) → Install Guide
- Python 3.x (v3.9 or later) → Install Here
- AWS CDK (Latest version) → Install via npm.
- Visual Studio Code → Download Here
- AWS Toolkit for VS Code (Optional, but recommended for easy interaction with AWS)
Configure AWS CLI
To configure AWS CLI, open a terminal and run:
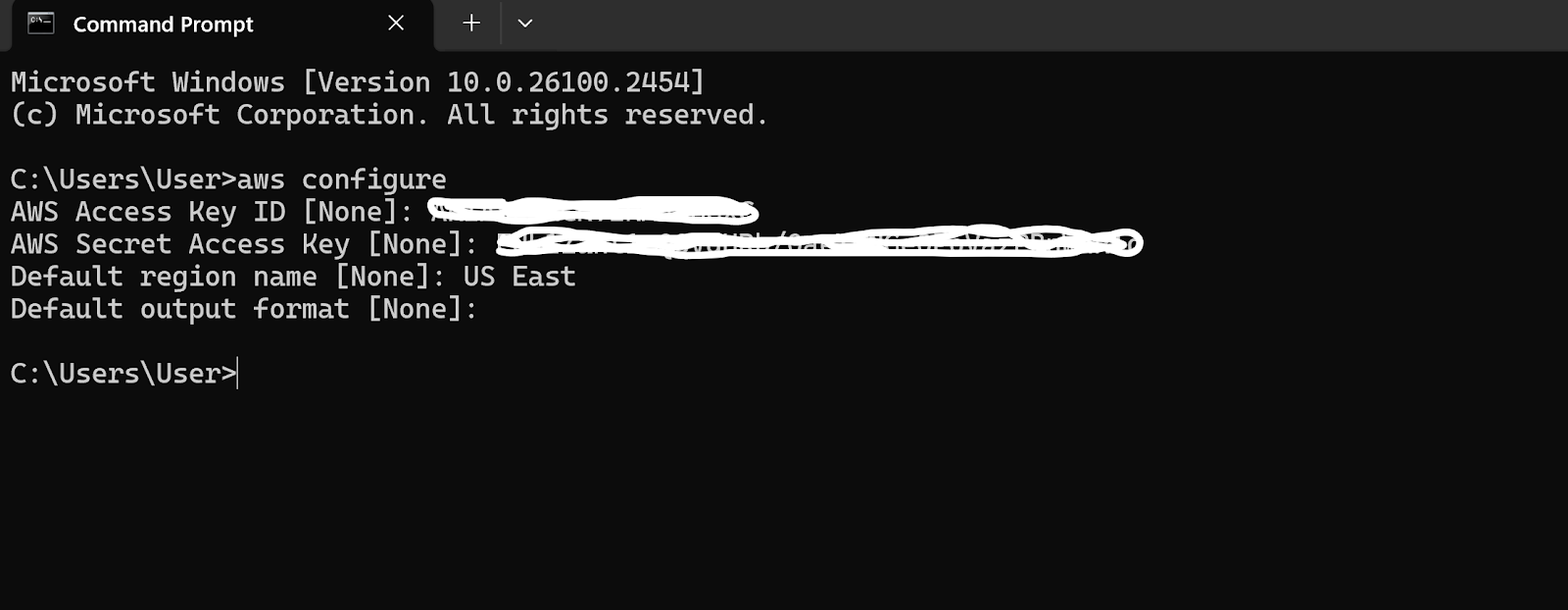
aws configure
Enter your AWS Access Key, Secret Access Key, default region, and output format when prompted.
Install AWS CDK

To install AWS CDK globally, run:
npm install -g aws-cdk
Verify the installation by checking the version:
cdk --version
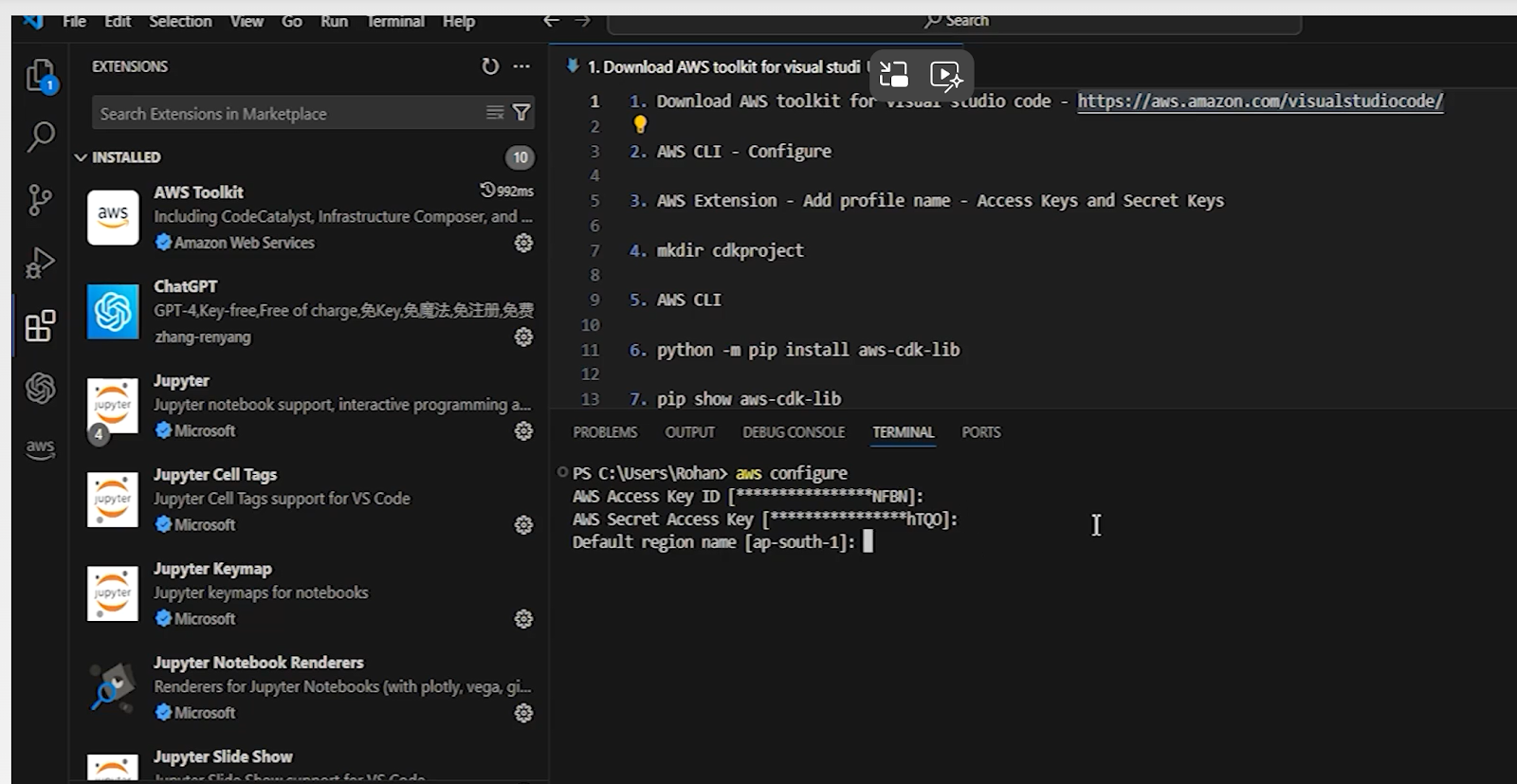
Login to AWS from Visual Studio Code
Click on the AWS logo on the left side, it will ask for credentials for the first time
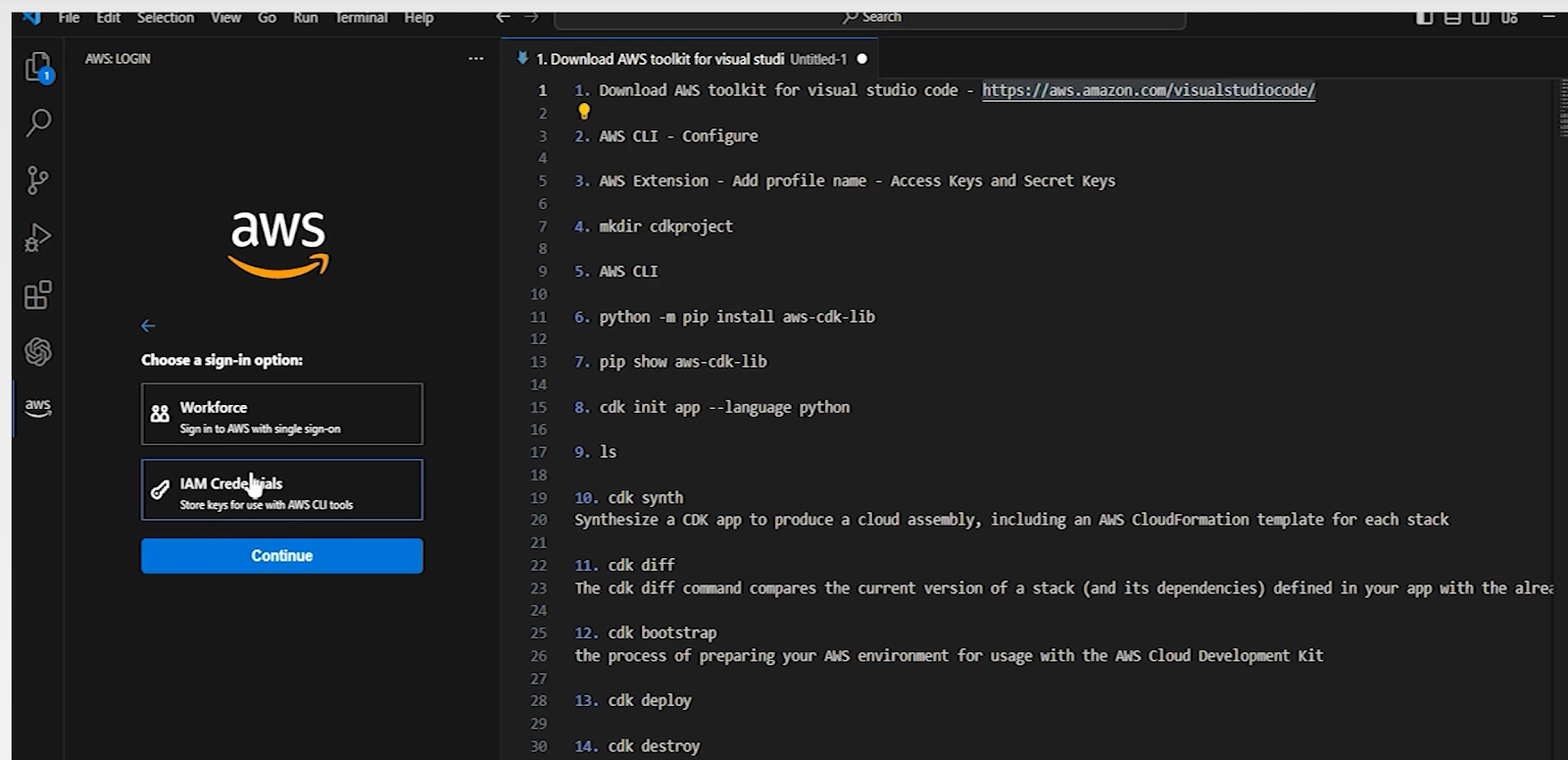
For the profile name use the Iam user name
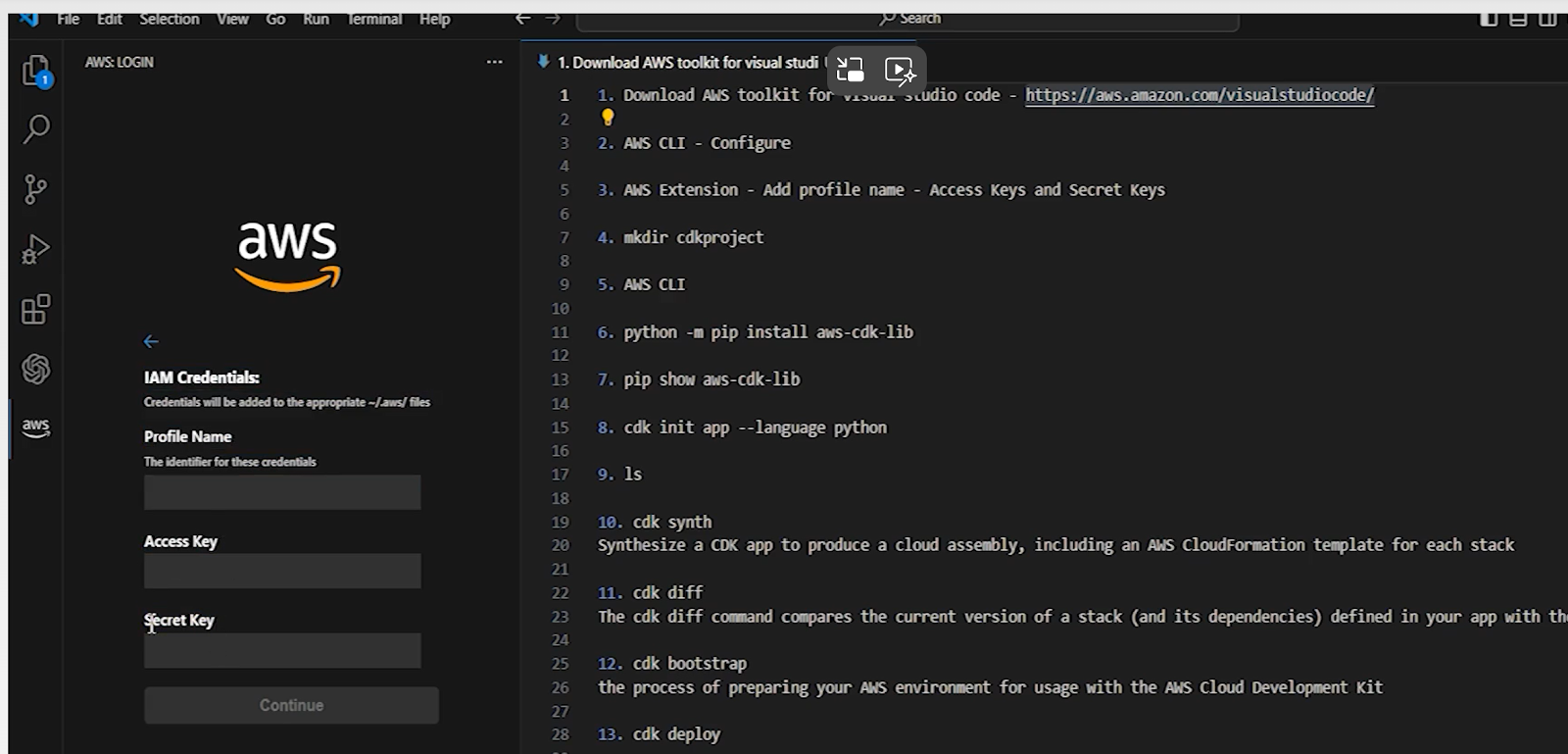
After signing in the IDE will appear as below.
Step 2: Create a New AWS CDK Project
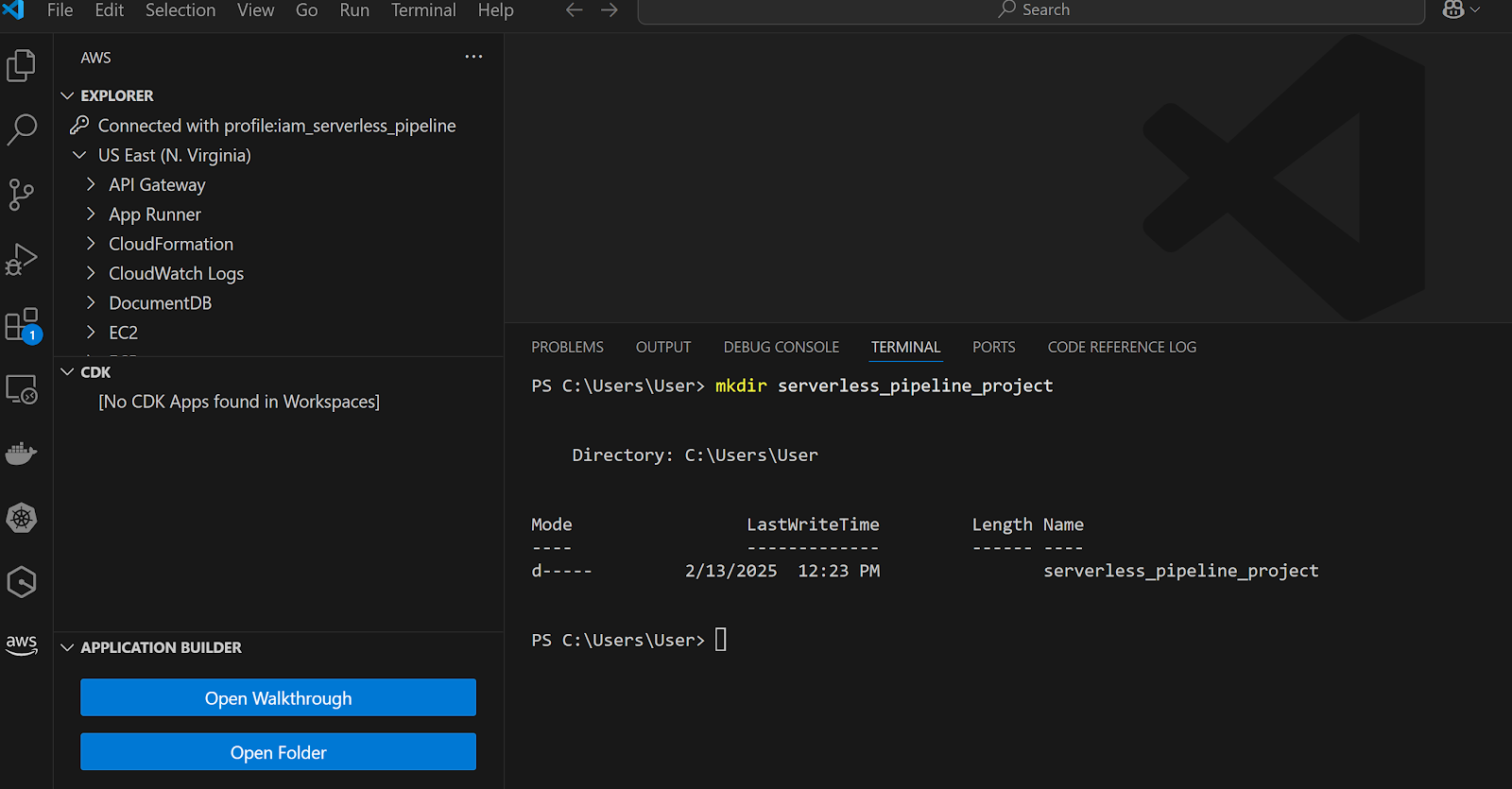
Open Visual Studio Code and create a new project directory:
mkdir serverless_pipeline_project
cd serverless_pipeline_project
Initialize the AWS CDK project with Python:
cdk init app --language python
This sets up a Python-based AWS CDK project with the necessary files.
Step 3: Set Up a Virtual Environment
Create and activate a virtual environment to manage your project’s dependencies:
python3 -m venv .venv
source .venv/bin/activate # For macOS/Linux
# OR
.venv\Scripts\activate # For Windowspython3 -m venv .venv
source .venv/bin/activate # For macOS/Linux
# OR
.venv\Scripts\activate # For Windows
Install the project dependencies:
pip install -r requirements.txt
Step 4: Define the Lambda Function
Create a directory for the Lambda function:
mkdir lambda
Write your Lambda function in lambda/handler.py:
import boto3
import os
s3 = boto3.client('s3')
bucket_name = os.environ['BUCKET_NAME']
def handler(event, context):
# Example: Upload processed data to S3
s3.put_object(Bucket=bucket_name, Key='output/data.json', Body='{"result": "ETL complete"}')
return {"statusCode": 200, "body": "Data successfully written to S3"}
Step 5: Define AWS Resources in AWS CDK
In the serverless_pipeline/serverless_pipeline_stack.py, define the Lambda function and the S3 bucket for data storage:
from aws_cdk import (
Stack,
aws_lambda as _lambda,
aws_s3 as s3
)
from constructs import Construct
class ServerlessPipelineProjectStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create an S3 bucket
bucket = s3.Bucket(self, "ServerlessPipelineProjectS3Bucket")
# Create a Lambda function
lambda_function = _lambda.Function(
self,
"ServerlessPipelineProjectLambdaFunction",
runtime=_lambda.Runtime.PYTHON_3_9,
handler="handler.handler",
code=_lambda.Code.from_asset("lambda"),
environment={
"BUCKET_NAME": bucket.bucket_name
}
)
# Grant Lambda permissions to read/write to the S3 bucket
bucket.grant_read_write(lambda_function)
Step 6: Bootstrap and Deploy the AWS CDK Stack
Before deploying the stack, bootstrap your AWS environment:
cdk bootstrap
Then, synthesize and deploy the CDK stack:
cdk synth
cdk deploy

You’ll see a message confirming the deployment.
Step 7: Test the Lambda Function
Once deployed, test the Lambda function using the AWS CLI:
aws lambda invoke --function-name ServerlessPipelineProjectLambdaFunction output.txt
You should see a response like:
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
Check the output.txt file; it will contain:
{"statusCode": 200, "body": "Data successfully written to S3"}
A folder called output will be created in S3 with a file data.json inside it, containing:
{"result": "ETL complete"}
Step 8: Clean Up Resources (Optional)
To delete all deployed resources and avoid AWS charges, run:
cdk destroy
Summary of What We Built
For this project, we configured AWS CDK within a Python environment. This was done to create and manage the infrastructure that is needed for a serverless ETL pipeline. The processing unit of the pipeline is an AWS Lambda serverless function which we developed for data processing. We also added Amazon S3 to use as a scalable and durable storage solution for raw and processed data. We deployed the required AWS resources using AWS CDK which automated the deployment processes. Finally, we confirmed that the entire setup was as expected by invoking the Lambda function and assured the data flowed properly through the pipeline.
Next Steps
In the future, I see multiple opportunities to improve and extend this serverless pipeline. An improvement that could be added is the use of AWS Glue for data transformation since it can automate and scale complicated ETL processes. Also, integrating Amazon Athena will enable serverless querying of the processed data which will allow for efficient analytics and reporting. Furthermore, we could use Amazon QuickSight for data visualization that can enhance the insights obtained from the data, allowing users to interact with the data presented on dashboards. These steps will build upon fundamentally what we have already built and will create a more comprehensive and sophisticated data pipeline.
By following this tutorial, you’ve laid the foundation for building a scalable, event-driven serverless pipeline in AWS using Python. Now, you can further expand the architecture based on your needs and integrate more services to automate and scale your workflows.

Author: Ashis Chowdhury, a Lead Software Engineer at Mastercard with over 22 years of experience designing and deploying data-driven IT solutions for top-tier firms including Tata, Accenture, Deloitte, Barclays Capital, Bupa, Cognizant, and Mastercard.