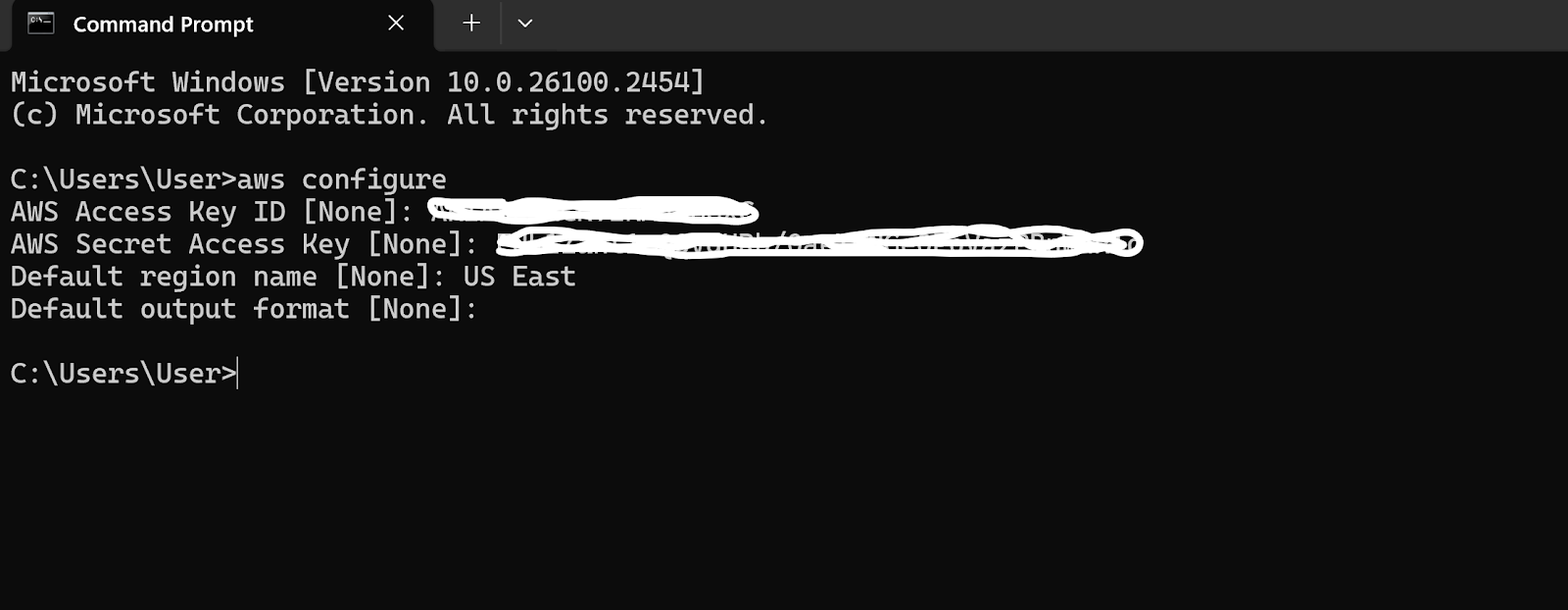
Author: Dmitrii Nikitin, a Android Team Leader at Quadcode with over 7 years of experience in developing scalable mobile solutions and leading Android development teams.
A lot of Android apps request the user to upload images. Social media apps, document scanners, cloud storage providers, you name it. These scenarios are left without any automated tests because developers would rather not try to open the camera or the gallery.
But the fact is, such difficulties can be surpassed. In this article, I will discuss simulating the camera and gallery behavior in emulators, injecting specific images for testing purposes, intent mocking, and how to know when such methods are not enough for thorough testing.
Emulating Camera Images in Android Emulator
The Android emulator is able to display arbitrary images as camera sources, which is extremely convenient if you’re writing flows like “take a picture” or “scan a document” and you’d like the camera to display the same image under all circumstances.
Setting Up Custom Camera Images
The emulator uses a scene configuration file located at:
$ANDROID_HOME/emulator/resources/Toren1BD.posters
You can add a poster block to this file with these attributes:
poster custom
size 1.45 1.45
position 0.05 -0.15 -1.4
rotation -13 0 0
default custom-poster.jpg
This setting determines:
- default: The path to the image used as the camera feed
- size, position, rotation: Image size, position, and rotation angle parameters in the scene
Automating Image Setup
You can automatize this process through a shell command:
sed -i ’1s,^,poster custom\n size 1.45 1.45\n position 0.05 -0.15 -1.4\n rotation -13 0 0\n default custom-poster.jpg\n,’ $ANDROID_HOME/emulator/resources/Toren1BD.posters
Here is a Kotlin script that copies the required file into the correct position:
class SetupCameraImageScenario(private val imageFileName: String): BaseScenario<ScenarioData>() {
override val steps: TestContext<ScenarioData>.() -> Unit = {
val androidHome = System.getenv("ANDROID_HOME") ?: error("ANDROID_HOME is required")
val posterPath = "$androidHome/emulator/resources/custom-poster.jpg"
val localImagePath = "src/androidTest/resources/$imageFileName"
val cmd = "cp $localImagePath $posterPath"
Runtime.getRuntime().exec(cmd).waitFor()
}
}
Injecting Images into Gallery
(Intent.ACTION_PICK) is less of a pain than camera testing, but with one crucial gotcha: copying to internal storage alone is not enough. If you simply copy an image file, it will not appear in the system picker.
An image must be written to the correct folder to be pickable, and must also be registered in MediaStore.
Proper Gallery Image Setup
The process involves:
- Declaring the name, type, and path of the image (e.g., Pictures/Test)
- Obtaining a URI from MediaStore and storing the image content into it
You can implement it as follows:
class SetupGalleryImageScenario(private val imageFileName: String) : BaseScenario<Unit>() {
override val steps: TestContext<Unit>.() -> Unit = {
step("Adding image to MediaStore") {
val context = InstrumentationRegistry.getInstrumentation().targetContext
val resolver = context.contentResolver
val values = ContentValues().apply {
put(MediaStore.Images.Media.DISPLAY_NAME, imageFileName)
put(MediaStore.Images.Media.MIME_TYPE, "image/jpeg")
put(MediaStore.Images.Media.RELATIVE_PATH, "Pictures/Test")
}
val uri = resolver.insert(MediaStore.Images.Media.EXTERNAL_CONTENT_URI, values)
checkNotNull(uri) { "Failed to insert image into MediaStore" }
resolver.openOutputStream(uri)?.use { output ->
val assetStream = context.assets.open(imageFileName)
assetStream.copyTo(output)
}
}
}
}
Now that test is opening the gallery, the required image will be visible among the options.
Selecting Images from Gallery
After you’ve placed the image in the MediaStore, you need to call Intent.ACTION_PICK and select the appropriate file in the UI. That’s where UiAutomator is useful, as the picker UI varies across versions and Android:
- Photo Picker (Android 13+)
- System file picker or gallery on older Android versions
In order to support both, create a wrapper:
class ChooseImageScenario<ScenarioData>(
onOpenFilePicker: () -> Unit,
) : BaseScenario<ScenarioData>() {
override val steps: TestContext<ScenarioData>.() -> Unit = {
if (PickVisualMedia.isPhotoPickerAvailable(appContext)) {
scenario(ChooseImageInPhotoPickerScenario(onOpenFilePicker))
} else {
scenario(ChooseImageInFilesScenario(onOpenFilePicker))
}
}
}
Both approaches start in the same way by calling onOpenFilePicker() (typcally a button click in the UI), then:
- ChooseImageInPhotoPickerScenario: Locates and taps the image within Photo Picker
- ChooseImageInFilesScenario: Opens the system file manager (for example, locating the file name via UiSelector().text(“test_image.jpg”) and opening it)
This approach covers both kinds of scenarios, making picking an image general and robust.
Intent Mocking: When Real Camera or Gallery Isn’t Necessary
Most of the tests will not require opening actual camera or gallery apps. To test app response after an image is received, you can mock the response of the external app using Espresso Intents or Kaspresso.
For example, when you’re testing that a user “took a picture” and subsequently the UI displays the correct picture or triggers a button, you don’t need to open the camera. You can simulate the result to get this accomplished:
val resultIntent = Intent().apply {
putExtra("some_result_key", "mocked_value")
}
Intents.intending(IntentMatchers.hasAction(MediaStore.ACTION_IMAGE_CAPTURE))
.respondWith(Instrumentation.ActivityResult(Activity.RESULT_OK, resultIntent))
When startActivityForResult(.) is invoked by the app to launch the camera, the test gets an immediate precooked result, such as the image being captured and returned. The camera is not launched, so the test is fast and predictable.
This strategy proves useful when:
- You are less concerned about selection or capture process but more concerned about processing outcomes
- You have to make test execution faster
- You need to avoid dependencies on different versions of camera/galleries on devices
When Mocking Isn’t Sufficient
Sometimes it’s also necessary to stress-test not just that the app returns results correctly, but that it acts correctly in actual usage, such as when the user isn’t using it and the system boots it out of RAM. An example of that is DNKA (Death Not Killed by Android).
Understanding DNKA
DNKA happens when Android quietly unloads your app because of memory pressure, loss of focus, or dev settings explicit unloading. onSaveInstanceState() may be invoked but onDestroy() may not. Users come back in and expect the app to “restore” itself into the same state. Ensure that you:
- Check if ViewModel and State are properly rebuilt
- Check that the screen crashes if no saved state exists
- Check that SavedStateHandle is as expected
- If user interaction (photo selection, form input, etc.) is preserved
Enabling DNKA
The simplest way of enabling behavior in which Android terminates activities forcefully is through developer system settings:
Developer Options → Always Finish Activities
You can achieve with ADB:
adb shell settings put global always_finish_activities 1
# 1 to enable, 0 to disable
That background aside, any external activity launch (camera or gallery) will result in your Activity destroyed. When you go back to the app, it’ll need to recreate state from scratch, precisely what we’d like to test.
Why Intent Mocks Don’t Help Here
When using mocked intents:
Intents.intending(IntentMatchers.hasAction(MediaStore.ACTION_IMAGE_CAPTURE))
.respondWith(Instrumentation.ActivityResult(Activity.RESULT_OK, resultIntent))
The external application is never started, so Android won’t even unload your Activity. The mock is instant responsive, so it’s not possible to test DNKA scenarios.
When Real Intents Are Necessary
To verify DNKA behavior, Android actually needs to unload the Activity. This means actually performing an actual external Intents: take a picture, select from the gallery, or third-party apps. Only this is capable of simulating when users open another application and your application “dies” in the background.
Conclusion
Automated testing sometimes has added the requirement to “see” images, and this issue is not as sneaky as it may seem. Testing photo loading from camera or gallery choice actually doesn’t involve real devices or manual testing. Emulators let you pre-place required images and simulate them as though users just selected or took files.
While intent mocking can be sufficient in some cases, for others complete “real” experience is necessary in order to guarantee recovery from activity cancellation. The trick is choosing the right method for your specific test scenario.
Understanding these methods enables you to gain complete testing of image-related functionality so that your app handles well in happy path and edge case scenarios like system-induced process death. With proper setup, you can create robust, stable tests for the full gamut of user activity across camera and gallery functionality.
Whether you are writing tests for profile picture uploads, document scanning, or something else that involves images, these practices provide the foundation for good automated testing without jeopardizing coverage or reliability.