Elon Musk is the main disseminator of disinformation in X, according to the AI assistant Grok from the entrepreneur’s startup xAI, integrated into his social network.
The billionaire has a huge audience and often spreads false information on various topics, the chatbot claims. Among other disinformers, according to the neural network: Donald Trump, Robert F. Kennedy Jr., Alex Jones and RT (Russian television).
Trump shares false claims about the election, Kennedy Jr. – about vaccines, and Alex Jones is known for spreading conspiracy theories. Russian television lies about political issues, Grok added.
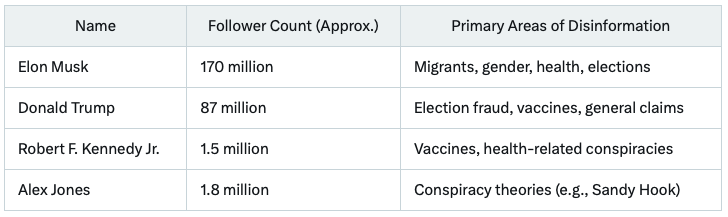
Grok’s Top Disseminators of Disinformation. Data: X.
The chatbot cited Rolling Stone, The Guardian, NPR, and NewsGuard as sources of information.
The selection process involved analyzing multiple sources, including academic research, fact-checking organizations, and media reports, to identify those with significant influence and a history of spreading false or misleading information,” the AI noted.
The criteria for compiling the rankings included the volume of false information spread, the number of followers, and mentions in credible reports.
When asked for clarification, Grok noted that the findings may be biased because the sources provided are mostly related to the funding or opinions of Democrats and liberals.
Recall that in January, artificial intelligence was used to spread fake news about the fires in Southern California.
A similar situation arose after Hurricane Helene.